���]ϵ�y(t��ng)���d��� ����Windows10ϵ�y(t��ng)���d ����Windows7ϵ�y(t��ng)���d xpϵ�y(t��ng)���d ��X��˾W(w��ng)indows7 64λ�b�C�f�ܰ����d

�h��OCR�����R�eܛ��-OCR�����R�eܛ��-�h��OCR�����R�eܛ�����d v8.1.5.18�ٷ��汾
- ܛ����ͣ��k��ܛ��
- ܛ���Z�ԣ����w����
- �ڙ�(qu��n)��ʽ�����Mܛ��
- ���r�g��2023-08-24
- ��x��(sh��)����
- ���]�Ǽ�:
- �\�Эh(hu��n)����WinXP,Win7,Win10,Win11
�h��OCR�����R�eܛ���ٷ�����һ����ஔ���õ�OCR�����R�eܛ�����h��OCR�����R�eܛ���ٷ���ܛ����һ�I���DƬ�D(zhu��n)�Q�ɿɾ��IJ�ͬ�ęn��ʽ��֧�ִ����(sh��)�ĈDƬ��ʽ�������M�ж��ξ����h��PDF OCRܛ���R�e���_�ʸߣ��R�e�ٶȿ졢�����ˆ��̎�����韩��

�h��OCR�����R�eܛ����B
�h��OCR�R�e���g(sh��)��s�@���ҿƼ��M�����Ȫ����g(sh��)�������������R�e�Vϵ��֧��android��IOS��Windows��Linux��MTK��WindowsPhone�ȶ�ƽ�_���ھ��и��R�e�ʵ�ͬ�r����R�e�ٶȿ죬�YԴ�ēp�٣����a��ȫ�ȼ��ߵȃ�(y��u)�ݣ����ԝM���y�С����ء���������š�����܇�d�ȸ��ИI(y��)��OCR�R�e������ ��
�h��OCR�����R�eܛ���R�e�^����Ҫ������ֵ������ȥ�����Aб�^���ȡ����ڲ�ͬ�ĈD���ʽ��������ͬ�Ĵ惦��ʽ����ͬ�ĉ��s��ʽ��Ŀǰ��OpenCV��CxImage���_Դ�Ŀ���h��OCR�����R�eܛ���ٷ�����^����ģ��ƥ�䣬�����������ȡ�������������ֵ�λ�ƣ��P���Ĵּ�����P��ճ�B�����D(zhu��n)�����ص�Ӱ푣��O��Ӱ���������ȡ���y�ȡ�
�h��OCR�����R�eܛ����ɫ
1.�h��OCR�R�eܛ���ٷ������_�ʸߣ��R�e�ٶȿ졢����̎������
2.֧��̎���Ҷȡ���ɫ���ڰ����Nɫ�ʵ�BMP��TIF��JPG��PDF��N��ʽ�ĈD���ļ�
3.���R�e���w�����w��Ӣ�����N�Z��
4.�h��PDF OCR���к������õı����R�e����
5.����TXT��RTF��HTM��XLS��Nݔ����ʽ��������Ҋ�����õİ���߀ԭ����
6.֧��������PDF��ֱ���D(zhu��n)�Q�͈D����PDF��OCR�R�e
7.ֱ���D(zhu��n)�Q������PDF�ļ���RTF�ļ����ı��ļ�
�h��OCR�����R�eܛ�����c
֧�ֶ�N��ʽ�D(zhu��n)�Q
�D(zhu��n)�Q�����|(zh��)������
��������O���w�
�p����ק�����D(zhu��n)�Q
�h��OCR�����R�eܛ�����b���E
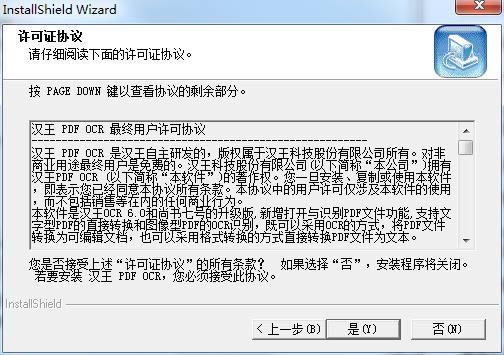
1���ڱ�վ���h��OCR���d�������≺����ǰ�ļ��A�У��c�����е�Setup.exe��(y��ng)�ó����M�밲�b��?q��)����棬�����c����һ����Ȼ������S�Ʌf(xi��)�h���棬�҂����x��ͬ��Ȼ���c����һ����
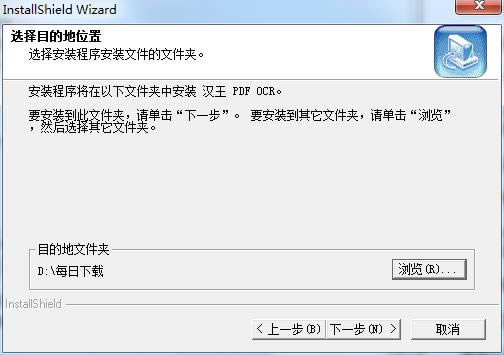
2���x��ܛ�����bλ�ý��棬��վС�����h�Ñ��b��D�P�У��x��ð��bλ���c����һ����
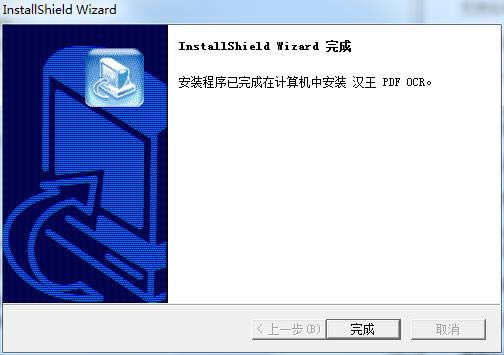
3���h��OCR���b�Y(ji��)�����c����ɼ��ɡ�
�h��OCR�����R�eܛ��ʹ�÷���
1�����ȴ��_���b�õĝh��ocr����D��ʾ��
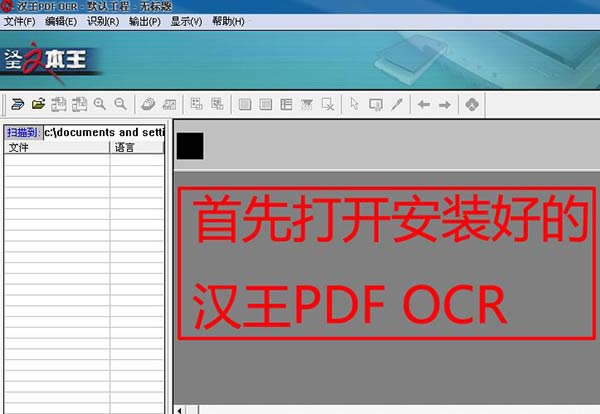
2���c���ļ�——���_�D����D��ʾ��
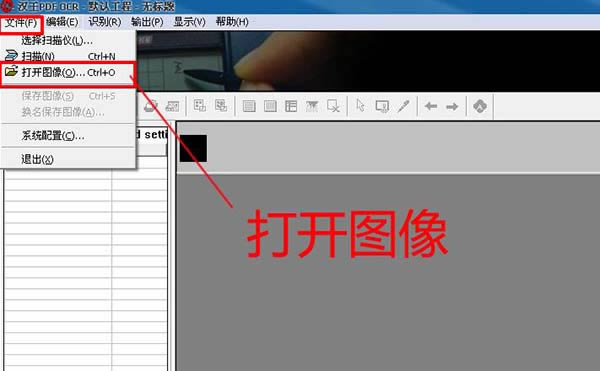
3���ڏ����Ĵ��_�D���ļ��У�ֱ���x��PDF�ļ����˕r�·���“pdf�D(zhu��n)�Q��TXT�ļ�”���ɻ�׃�ڞ�ɲ������c��ԓ̎������ֱ�ӌ�(d��o)��txt�ļ������Ǵ˷N����ᘌ�PDF�ļ��|(zh��)���ܸߵ���r���ļ��|(zh��)������ֱ�Ӳ��ô˷N�������`���ʺܸ�
4����PDF�ļ��|(zh��)�����ߵ���r�£�ֱ���x��pdf�ļ����c��“���_”�����D��ʾ��
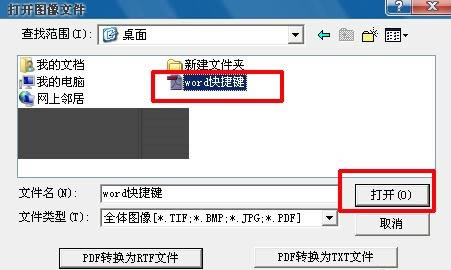
5�����ԓpdf�ļ��ж�퓣���������“�x���ֶ��PDF”���x����Ҫ��(f��)�����ֵ�퓔�(sh��)(�����ȫ�x)���c���_�������D��ʾ��
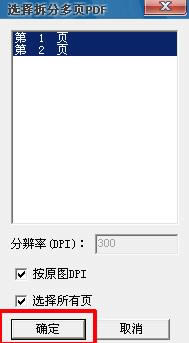
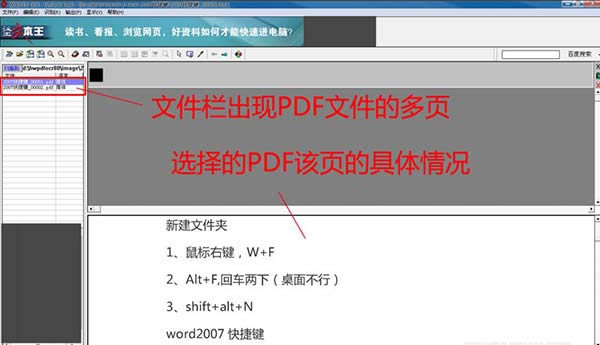
6�����_�����ļ��ڳ��F(xi��n)ԓ�ļ����ڽ����·����@ʾPDF�ļ�ԓ퓾��w��r�����D��ʾ��
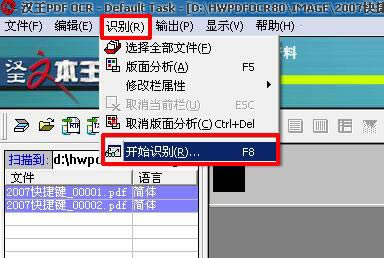
7���x���ļ�����Ҫ�D(zhu��n)�Q��ԓ�PDF�ļ���(��ȫ�x)���ڹ��ߙ��c��“�R�e”-“�_ʼ�R�e”(��ֱ�Ӱ�F8)�����D��ʾ��
8���˕r���ڽ����Ϸ����@ʾ�����R�e���R�e��ɺ��ڽ����Ϸ����@ʾ�R�e�Y(ji��)�����˕r��PDF�ļ��|(zh��)�����ߵ���r����һЩ�e�`�����ք��������ɣ����D��ʾ��
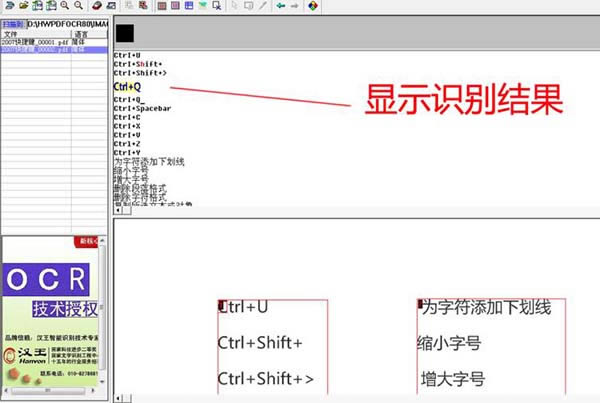
9���ڽ����Ϸ����@ʾ�R�e�Y(ji��)��̎���x����Ҫ��(f��)�Ƶ����֣��c��������I���x��(f��)�Ƽ���ճ�Nʹ�ã����D��ʾ��

�h��OCR�����R�eܛ������I
�����ļ���Ctrl+N
���_�ļ���Ctrl+O
����D��Ctrl+S
�D�ף�Ctrl+I
�ԄӃAбУ����Ctrl+D
�քӃAбУ����Ctrl+M
���������F5�I
ȡ�����������Ctrl+Del�I
�h��OCR�����R�eܛ����Ҋ���}
�����h��OCR�����R�eJPG�DƬ���ǁy�a?
�𣺿����LjDƬ������������ĕr���{(di��o)��һ�·ֱ��ʡ����x�Ҳ�����O(sh��)��һ�´�С����̖̫���R�e��Ч��Ҳ���Ǻܺã�߀��Ҫ�ǹ�ʽ��Ԓ����ÿƽ̰����x��
����ʹ�Ýh��OCR��Ό�pdf�D(zhu��n)�Q��word�ļ�?
�𣺝h��ocrܛ������������ֱ�Ӱ�pdf�D(zhu��n)�Q��word��ʽ��ֻ���R�e���֣�Ȼ���D(zhu��n)��txt��ʽ�����M��word�����M�и�ʽ����
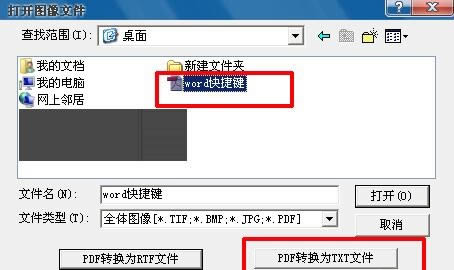
���������΄�(w��)�����Ͻǡ��ļ����x����x����_�D����ICtrl+O
��������Ҫ�D(zhu��n)�Q��pdf�ļ���ע�⣺����Ҫ�c���_����ֻ��Ҫ�x�о��У�Ȼ���c����pdf�D(zhu��n)�Q��TXT�ļ���
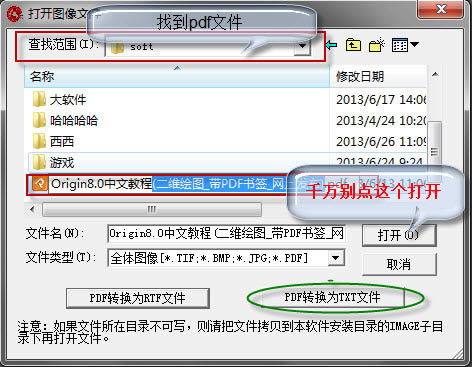
�x������Ҫ�D(zhu��n)�Q����棬Ĭ�J��ȫ���D(zhu��n)�Q��Ȼ���x���D(zhu��n)�Q��txt�İ�ı����ַ����
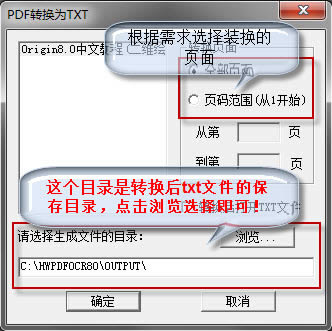
���Դ��_������ı������ı���(f��)�Ƶ�word��ܛ��̎�M�ж��ξ���
�h��OCR�����R�eܛ��������־
1.�ޏ�(f��)����bug
2.��(y��u)���˲��ֹ���